
시작하기에 앞서 Udemy강의(Certified Kubernetes Administrator (CKA) with Practice Tests) 에서 필요한 내용만 발췌해서 작성하였음을 알립니다.
1. cluster architecture
아래의 그림처럼 배를 비유로 들어 쿠버네티스 아키텍처에 대해 설명하겠다.
쿠버네티스의 목표는 컨테니어 형태로 된 어플리케이션을 자동화 된 방법으로 호스팅하는 데 있다.
- 어플리케이션에서 필요한 만큼 인스턴스를 띄우거나
- 어플리케이션 내 서로 다른 서비스 간 커뮤니케이션을 쉽게 하도록
이것들을 위해서는 많은 컴포넌트들이 필요하다.
배를 비유로 들면,
- 실제로 컨테이너를 싣고 바다를 돌아다니는 화물선 (=워커 노드)
- 이러한 화물선들을 관리하는 관리선 (=마스터 노드)
쿠버네티스 클러스터는 여러 개의 노드들로 구성되어 있다
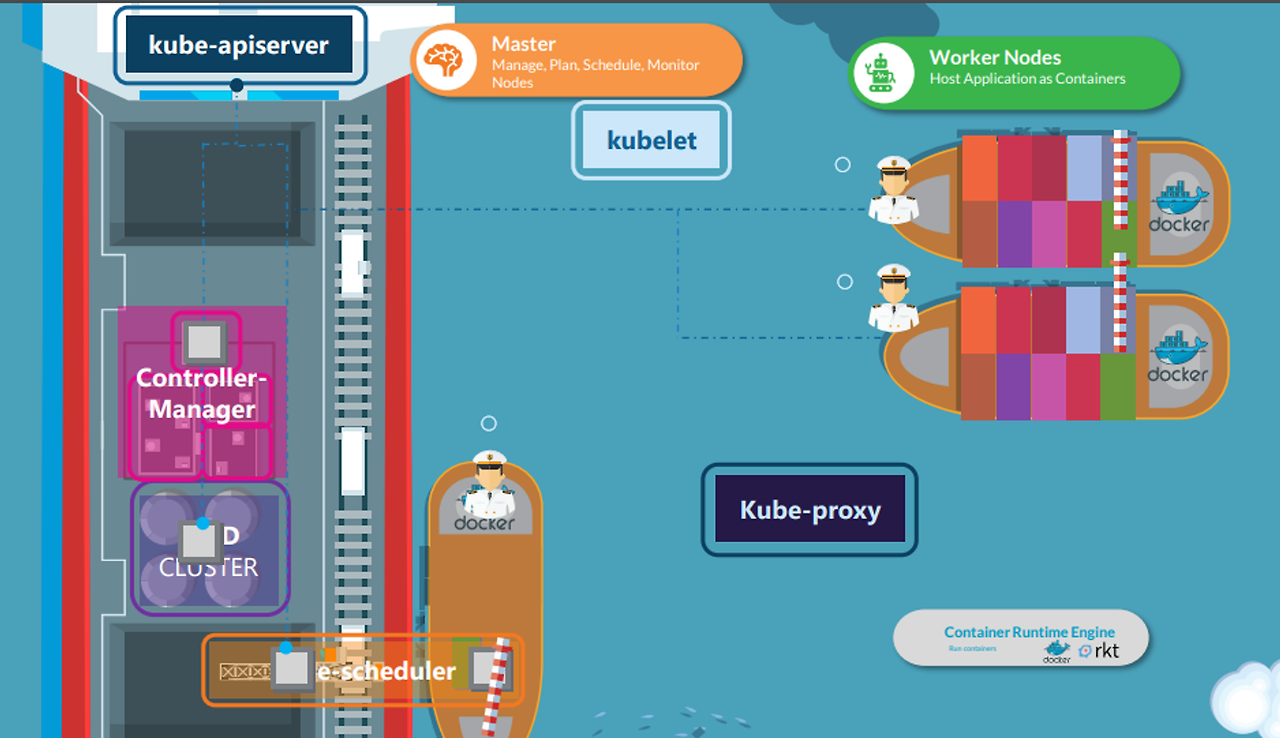
마스터 노드 (관리선)
- 화물선에 컨테이너를 싣는 역할. 또 어떻게 실을지 계획을 세움
- 적절한 화물선을 선택
- 각종 정보 저장, 컨테이너 관리, 모니터링, 통신 등 모든 것을 관리함
- 여러 개의 컴포넌트들로 구성 (control plane component)
Control Plane Component
- etcd: 어느 곳에 어느 컨테이너가 로드되어 있고, 언제 로드 되었고 등등 각종 정보를 저장하는 키 밸류 저장소
- scheduler: 해당 컨테이너의 크기나 현재 워커 노드의 상황 등을 토대로 해당 컨테이너가 어느 노드에 로드되어야 하는지 결정하는 역할
- controller manager: 트래픽 컨트롤, 컨테이너나 노드 고장 등을 관리하는 컴포넌트. 노트 컨트롤러, replication 컨트롤러가 있음.
- api server: 위 컴포넌트들을 서로 통신하게 만드는 컴포넌트. 클러스터 안에서 일어나는 모든 동작에 대해 조율하는 역할. k8s api를 노출시켜 이를 통해 외부 유저들이 k8s 클러스터에 대해 일련의 행위를 가능하게 함.
Container Runtime Engine
- 컨테이너를 실행하는 소프트웨어
- 대표적으로 Docker 를 사용
- 모든 노드(마스터 노드 포함)에는 Docker가 설치되어 있어야 함
- 쿠버네티스는 Docker말고도 ContainerD나 Rocket도 지원함
워커 노드 (화물선)
실제로 컨테이너가 실리는 곳
Kubelet
- 화물선에서 선장 역할
- 각 노드에서 실행되는 에이전트
- 워커 노드에서 일어나는 모든 활동에 대해 책임이 있음
- 마스터 노드와 통신 (특히 클러스터에 조인하는 경우)
- 해당되는 컨테이너를 싣고 그 결과를 마스터에 공유하는 일
- 자신의 노드와 컨테이너에 대한 상태도 마스터에 보고함
- kube api 서버에서 명령을 받아서 컨테이너를 실행하거나 없애거나 하는 일을 함
- kube api 서버는 정기적으로 kubelet으로 부터 노드와 컨테이너에 대한 상태 체크 리포트를 받음
kube-proxy
- 워커 노드 간 통신을 담당함
- 노드 내에 있는 컨테이너들이 다른 노드에 있는 컨테이너와 통신이 되게 하는 역할
2. Docker vs ContainerD
처음엔 Docker가 컨테이너 도구로서 독보적이였다. 그래서 도커와 쿠버네티스가 협업 관계였다.
하지만 쿠버네티스가 컨테이너 오케스트레이터로서 인기가 높아지게 되었고, rkt 같은 다른 컨테이너 런타임과도 협업하길 원했다.
그래서 kubernetes는 컨테이너 런타임 인터페이스, CRI라는 인터페이스를 만들었다.
CRI는 어떤 공급업체든 쿠버네티스의 컨테이너 런타임으로 작업하게 해준다.
(OCI 표준을 준수하는 한)
그런데 Docker는 CRI 표준을 지원되도록 만든게 아니다!!
Docker 는 CRI가 나오기 훨씬 전에 만들어 졌고, Docker는 여전히 주요 컨테이너 도구였기 때문에 쿠버네티스가 한 수 접고 Docker에 맞춰줘서 지원했다.
그래서 쿠버네티스는 dockershim을 도입해줬다.
컨테이너 런타임 인터페이스 밖에서 Docker를 지속 지원하는 임시방편도구다.
하지만 Docker도 아래 그림을 보면 알 수 있듯이 런타임으로만 이루어져있지 않았다.
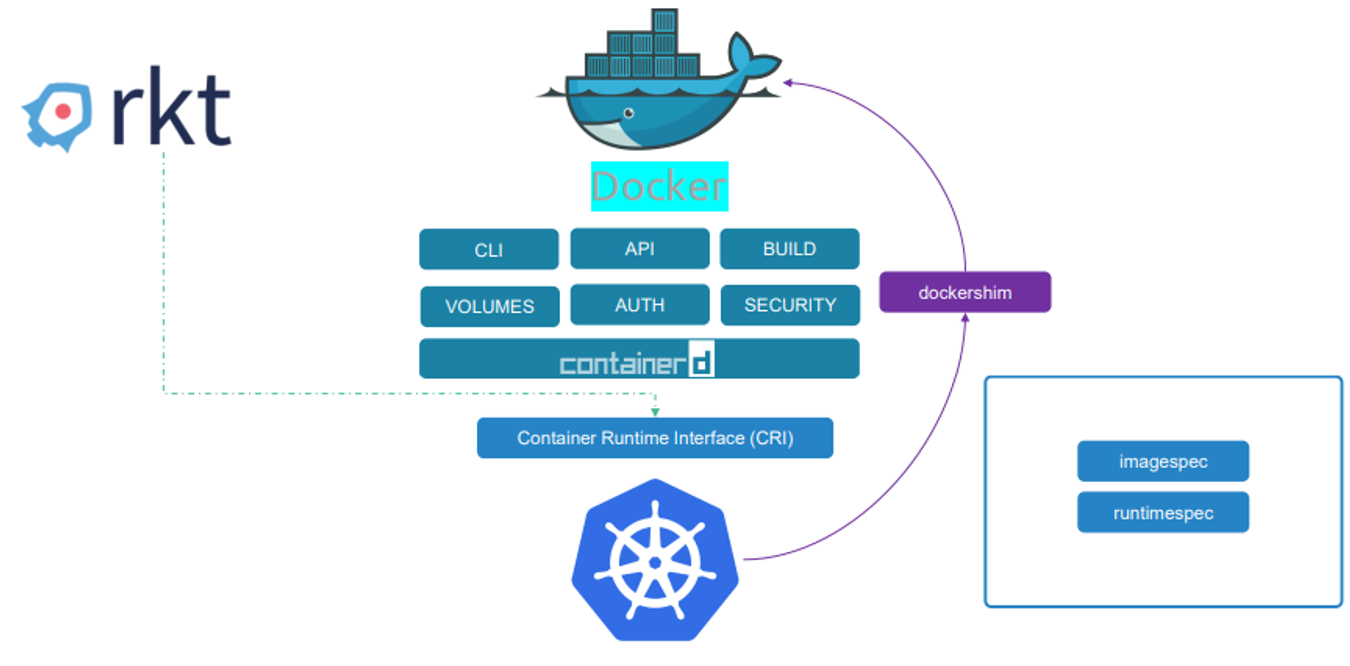
containerd 는 도커와 별도로 런타임으로 사용될 수 있다.
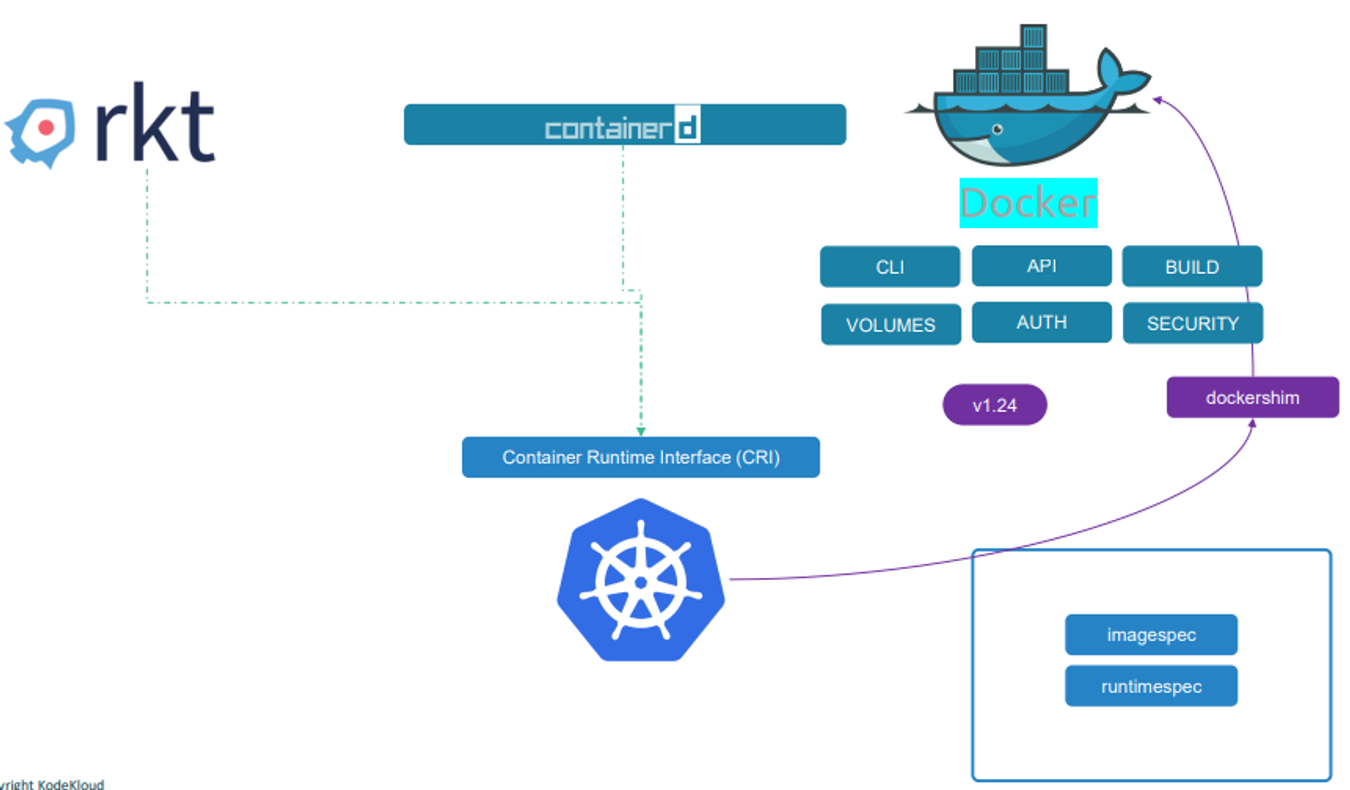
하지만 도커심을 유지하기 위한 노력이 너무 컷다
따라서 kubernetes는 도커심 지원을 해제했다.
모든 Docker 이미지는 계속 작동한다. Docker는 OCI 표준에서 이미지팩을 사용하기 때문이다.
containerd 에 대해 자세히 알아보자.

DOCKER와 별개로 동작하고 설치도 가능하다.
컨테이너d만 장착된 컨테이너를 그러면 어떻게 실행할까?
컨테이너d를 설치하면 ctr이라는 명령줄 도구가 나온다.
이미지를 가져오고 컨테이너를 실행할 수 는 있지만 사용자친화적이지 않다.
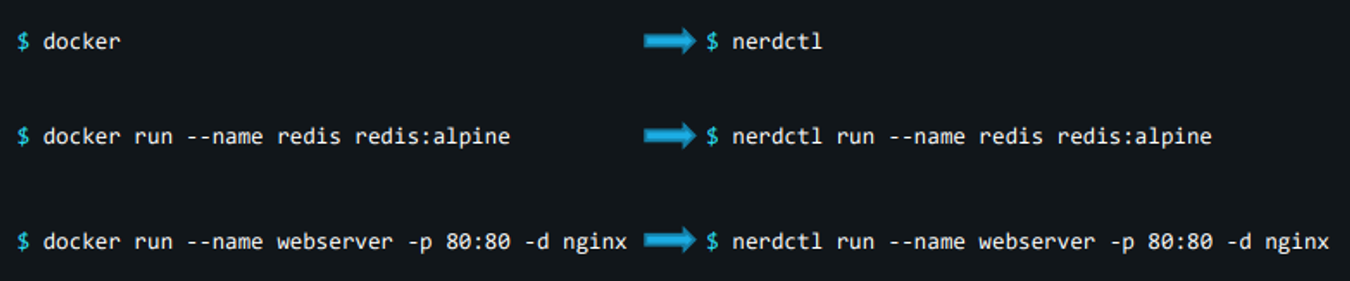
따라서 더 나은 대안으로는 CLI - nerdctl 도구가 있다.
nerdctl 도구는 명령줄 도구로 Docker와 아주 유사하다.
CLI - circlt 에 대해 얘기해보자
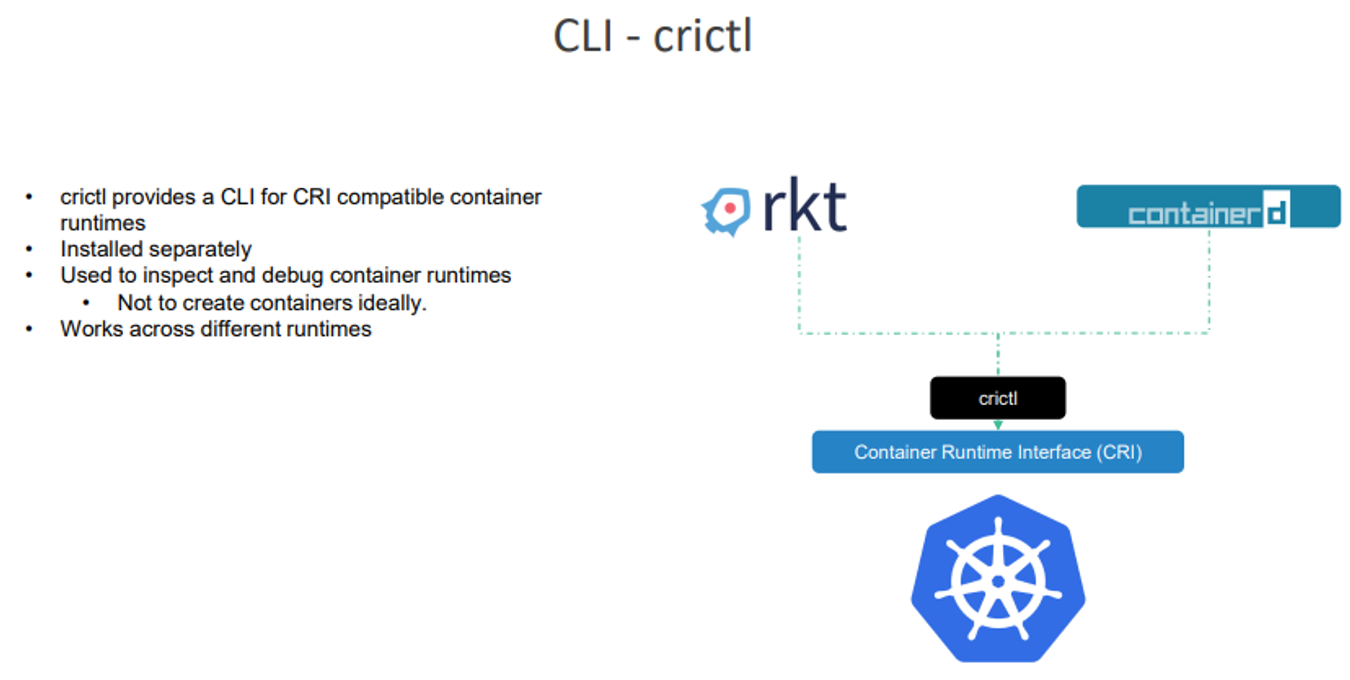
다른 도구들과는 달리 kubernetes 관점에서 다른 컨테이너 런타임에 걸쳐 작동한다. 그래서 별도 설치가 필요하며 검사와 컨테이너 런타임에 사용된다.
컨테이너 제작에는 사용되지 않고 디버깅 목적으로 사용된다.
3. ETCD
분산 시스템을 계속 실행하는 데 필요한 중요한 정보를 보관하고 관리하는 데 사용되는 분산 오픈소스 키-값 저장소
etcd는 클러스터에 관한 정보를 저장한다.
nodes, pods, configs, secrets, accounts, roles …
보통 관계형 db들은 계속 열을 추가하다보니 빈공간이 생긴다.
key-value store 는 정보를 문서나 페이지 형태로 보관한다.
각 개인은 문서를 받고 그 개인에 대한 모든정보는 해당 파일에 저장된다.
간단한 key와 값을 저장하고 회수할 수 있지만, 데이터가 복잡해지면 json 같은 데이터 포맷에서 트랜잭션하게 된다.
💡 여기서 트랜잭션이란!!
사용자의 요청을 처리하기 위해 여러 개의 작업이 필요한 경우, 이러한 작업들을 하나의 알고리즘처럼 묶어서 처리하는 것을 트랜잭션이라고 합니다.
예를 들어, 은행에서 돈을 이체하는 경우를 생각해보세요. 돈을 보내는 계좌에서 돈을 빼는 작업과, 받는 계좌에 돈을 넣는 작업, 이 두 가지 작업이 있습니다. 이 두 작업을 트랜잭션이라는 하나의 큰 단위로 묶어서 처리합니다. 만약 돈을 보내는 계좌에서 돈을 빼는 작업은 성공했는데, 받는 계좌에 돈을 넣는 작업이 실패한다면, 전체 트랜잭션은 실패로 간주되고, 처음부터 다시 시작하게 됩니다.
설치는 github에서 바이너리를 다운로드한다.
ETCD 실행 파일을 실행한다
포트 2379의 신호를 자동으로 듣는 서비스가 시작된다.
ETCD와 함께 오는 기본 클라이언트는 ETCD control 클라이언트다.
키 값 쌍을 저장하고 회수할 수 있다.
4. Kube - api server
쿠버네티스에서 kube-apiserver는 클러스터의 중추적인 역할을 한다.
사용자 또는 클라이언트의 요청을 받아 적절한 작업을 수행하도록 지시한다. 그 과정은 대략적으로 다음과 같다
- 사용자가 kubectl 명령을 실행하거나 다른 방식으로 API 요청을 보낸다. 이 요청은 주로 RESTful API를 통해 전달된다.
- kube-apiserver는 이 요청을 받아 인증, 인가, 그리고 요청 유효성 검사(admission control) 과정을 거친다.
- kube-apiserver는청이 유효하다고 판단되면, 이 요청을 etcd에 기록한다. etcd는 쿠버네티스 클러스터의 중요한 데이터를 저장하는 분산 키-값 저장소다.
- kube-scheduler는 새로운 파드 생성 요청 등을 감지하고, 이 파드를 실행할 적절한 워커 노드를 결정한다. 이 결정은 노드의 리소스 사용률, 파드의 리소스 요구량, 노드 선호도 등을 고려하여 이루어진다.
- 워커 노드의 kubelet은 kube-apiserver를 주기적으로 조회하여 자신에게 할당된 작업이 있는지 확인한다.
- kubelet이 새로운 작업을 발견하면, 해당 노드에서 Docker(또는 다른 컨테이너 런타임)를 통해 컨테이너를 실행한다.
- 컨테이너의 상태 변경, 오류 등은 kubelet에 의해 kube-apiserver로 다시 보고되고, 이 정보는 etcd에 업데이트된다.
5. Kube Controller Manager
Kube Controller Manager 는 다양한 컨트롤러를 관리한다.
- 상태를 항상 확인하고
- 상황을 재조정하기 위한 조치를 취한다. (kube api server를 통해)
- 5초마다 노드의 상태를 확인한다.
- 40초 후에야 신호가 잡힌다.
- 수신불가 후 다시 표시? 확인 하는데 5분이 걸린다.
6. Kube Scheduler
node pods의 일정 관리를 책임진다.
💡 kube scheduler는 어떤 pods 가 어느 node에 들어갈지만 결정한다.
pods를 node에 두는 일은 kubelet이 한다!!
스케줄러는 각 pods를 보고 적합한 노드를 찾으려고 한다.
cpu와 메모리 요구사항 모음이 있다.
2단계를 거쳐 적합한 노드를 찾는다.
- 스케줄러가 pod에 맞지 않는 노드를 걸러낸다.
- 가장 적합한 노드를 표시한다. 우선순위 함수를 이용해서 0~10까지의 점수로 노드에 점수를 매긴다. 가령, 노드에 pod를 설치하고 나서 여유공간을 계산한다. 이런 방식은 사용자 지정으로 해줄 수도 있다.
7. kubelet
배의 선장님이다. 선내의 모든 활동을 지휘한다.
마스터쉽(master node)과의 유일한 연락망이다.
설치는 작업자 노드에 반드시 수동으로 kubelet을 설치해야한다.?
설치 관리자를 다운로드해서 서비스로 실행하는거다.
8. kube proxy
kube-proxy는 쿠버네티스 클러스터의 각 노드에서 실행되는 프로세스다.
kube-proxy는 이름 그대로 프록시, 즉 '대리인'의 역할을 한다.
쿠버네티스 클러스터 내의 각 노드에서 실행되면서 네트워크 통신을 도와주는 역할을 한다.
예를 들어, A라는 노드가 B라는 노드에 데이터를 보내고 싶을 때, 직접 보내는 게 아니라 kube-proxy를 통해 데이터를 전달한다.
이런 방식으로 클러스터 내의 모든 노드들이 서로 통신을 할 수 있게 도와주는 것이 kube-proxy의 주요 역할이다.
간단히 말하자면, kube-proxy는 쿠버네티스 클러스터에서 '통신 담당 직원' 같은 존재
9. Recap - pods
container : 컨테이너는 애플리케이션과 그것을 실행하는 데 필요한 모든 환경을 하나로 묶은 것
pod: 파드는 쿠버네티스에서 배포하는 가장 작은 단위. 파드는 하나 이상의 컨테이너를 포함할 수 있다.
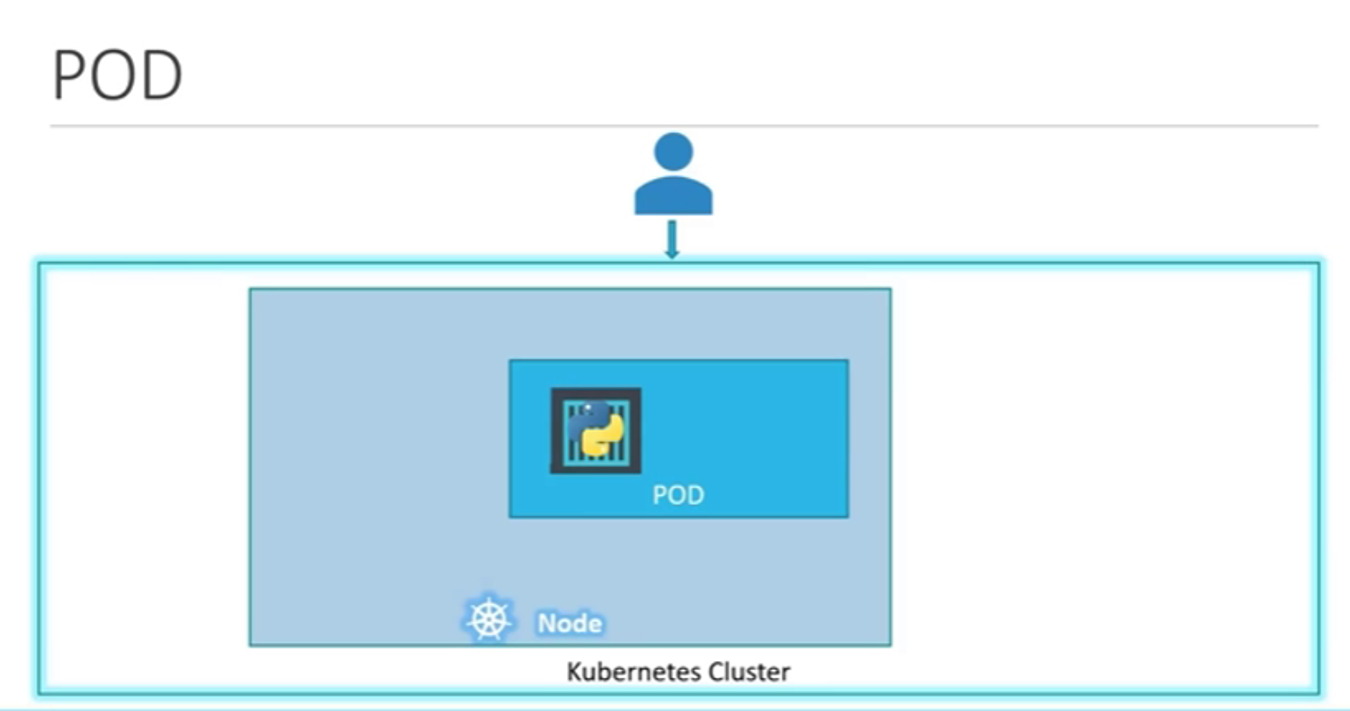
10. pods 생성하기
쿠버네티스는 YAML 파일을 포드, 복제본, 배포, 서비스 등 개체 생성을 위한 입력으로 사용한다.
전부 비슷한 구조 형식을 띄고있다.
쿠버네티스 정의 파일은 항상 4개의 상위 레벨 필드를 포함해야 된다.
apiVersion, kind, metadata, spec 이다.
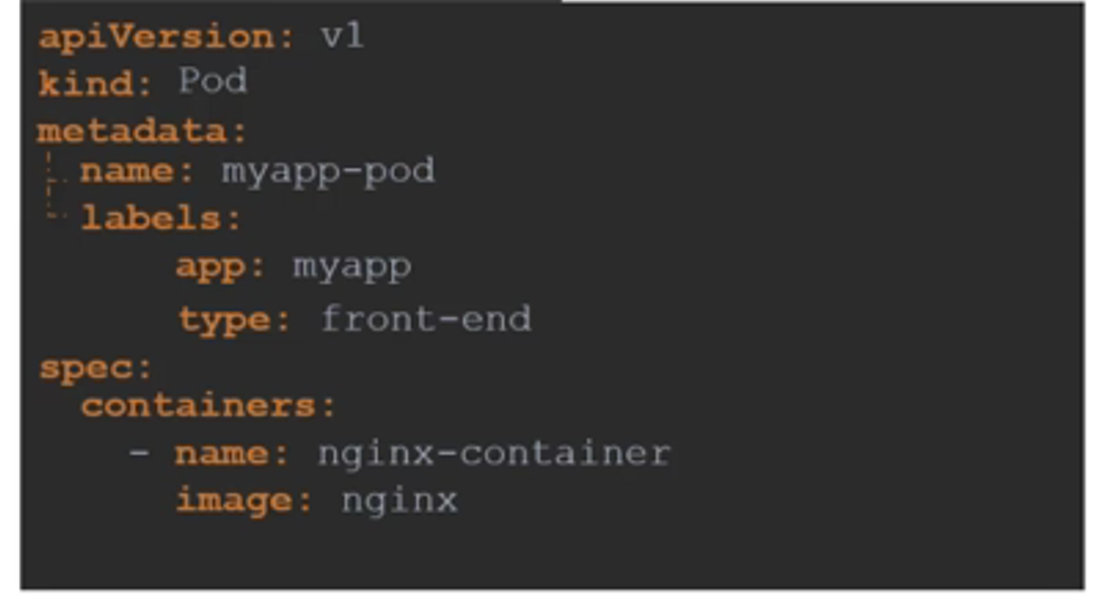
apiVersion
개체를 생성할 때 사용하는 쿠버네티스 API 버전이다.
우리가 무엇을 만들지에 따라 올바른 버전을 사용해야 한다.
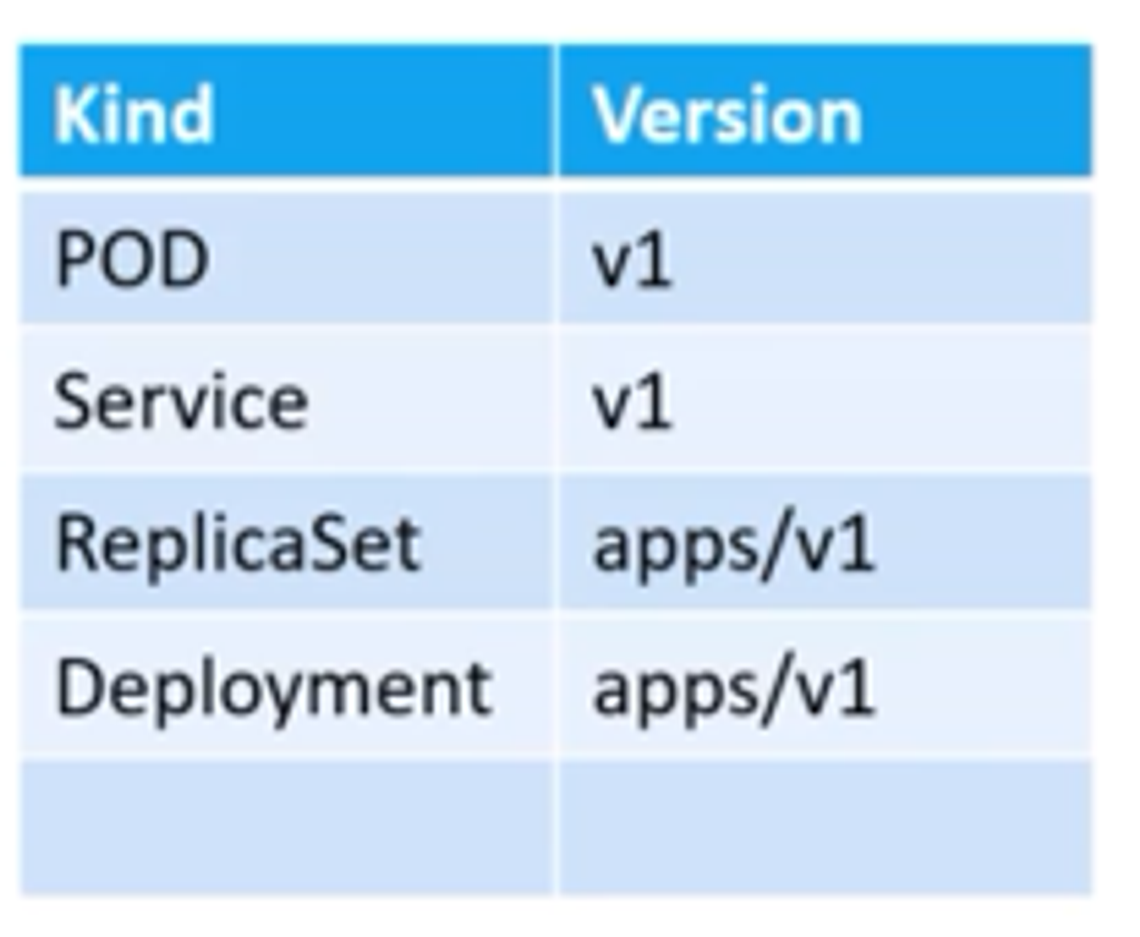
kind
우리가 만들려는 개체 유형을 가르킨다.
metadata
메타데이터는 개체 위의 데이터다.
이름이나 라벨 같은것이다.
(라벨은 음 분류별로 정리해두는 것과 같이 필터링 해주는 역할을 할 수 있다.)
작성시 빈칸에 유의해야한다!!
spec
생성하려는 개체에 관련된 추가정보를 제공한다.
이후 해당 yaml 파일을 실행하려면 아래와 같이 명령어를 입력하자.
kubectl creat -f pod-definition.yaml
11. pods 연습 테스트
1. pod의 개수 체크
kubectl get pods
2. nginx 이미지를 사용해서 pod 생성
kubectl run mypod --image=nginx
3. 새로 생성된 pod의 이미지가 무엇인가?
kubectl describe pods newpods-kjb59
4. 생성된 pod는 어느 노드에 있나요?
controlplane ~ ➜ kubectl get nodes
NAME STATUS ROLES AGE VERSION
controlplane Ready control-plane,master 12m v1.29.0+k3s1
또는
controlplane ~ ✖ kubectl describe pods newpods-kjb59
Name: newpods-kjb59
Namespace: default
Priority: 0
Service Account: default
Node: controlplane/192.13.199.6
5. Pod 웹앱에는 몇 개의 컨테이너가 포함되어 있나요?
> kubectl describe pod hiapp
Name: hiapp
.......
IPs:
IP: 10.42.0.13
Containers:
nginx:
Container ID: containerd://36b695ccc7152b711160c5436b782c9996e4628706c7f4c537c71f342b86ba74
.....
agentx:
Container ID:
....
6. hiapp 의 상태는?
hiapp 1/2 ImagePullBackOff 0 5m40s
에러가 나있다. (이미지를 못 불러옴)
7. kubectl get pods 명령 출력의 READY 열은 무엇을 나타냅니까?
각 pods내에서
현재 준비된 컨테이너 수 / 전체 컨테이너 수
8. webapp pod를 지워라
controlplane ~ ✖ kubectl delete pod webapp
pod "webapp" deleted
9. 이름이 dorong이고 이미지가 dorong123인 새 포드를 생성합니다.
kubectl run dorong --image=dorong123
10. 이제 이 Pod의 이미지를 dorong로 변경하세요.
kubectl edit pod dorong
들어가서 이미지 부분을 redis 로 변경하고 ! 후 wq 쓰고 나오면 자동 업데이트가 된다.
12. Replicaset
replica 컨트롤러에 대해 알아보도록 하자.
replica가 필요한 이유는 간단하다. 하나가 고장나도 시스템이 계속 동작하게 하기 위해서.
고가용성을 제공하기 위해서이다!
꼭 pod가 2개가 아니여도 된다. 1개의 pod가 동작중 고장나더라도 자동으로 새로운 pod를 동작시킬 수 있다.
또한,
복제 컨트롤러는 클러스터 내 여러 노드로 뻗어 있다. 따라서 수요가 증가하면 앱 스케일도 조정 할 수 있다.
Replication Controller | Replica Set
이 두가지의 차이점을 알아두어야 한다.
둘다 용도는 같지만, replication controller는 구식 기술로 현재는 replica set으로 대체되고 있다.
아래는 Replication Controller 정의 파일을 만드는 과정이다.
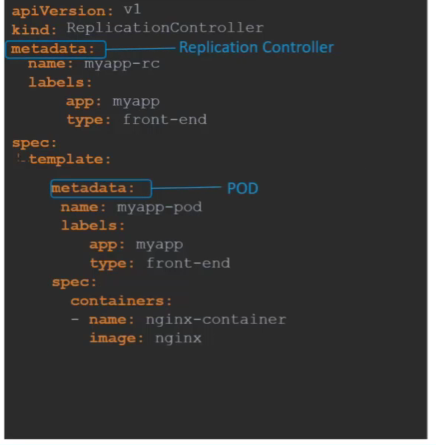
복제 컨트롤러의 템플릿 섹션에 pod의 metadat와 spec이 들어가게 된다.
그 이후 몇개의 복제본을 생성할 건지 아래와 같이 입력해주면 된다.
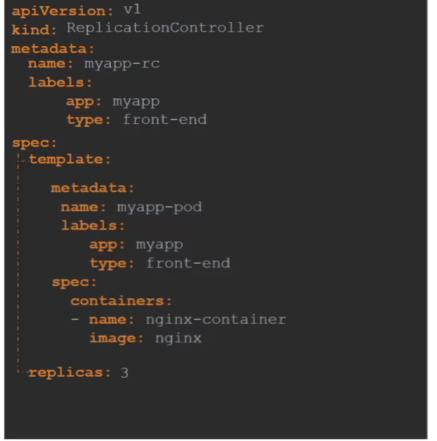
이후 create 명령어를 사용하여 yaml 파일을 실행시킨다.
kubectl create -f rc-definition.yml
그리고 아래의 명령어로 확인해보면 된다.
kubectl get replicationcontroller
아래는 Replica set 정의 파일을 만드는 과정이다.
Replicaation Controller 와의 차이점은 다음과 같다.
1. apiVersion이 다르다.
2. selector 부분이 추가된다. 아래에 어떤 포드가 있는지 지정해야 된다. 왜냐하면 replica set에선 하위 pods 가 아닌 다른 pods도 관리 할 수 있다.
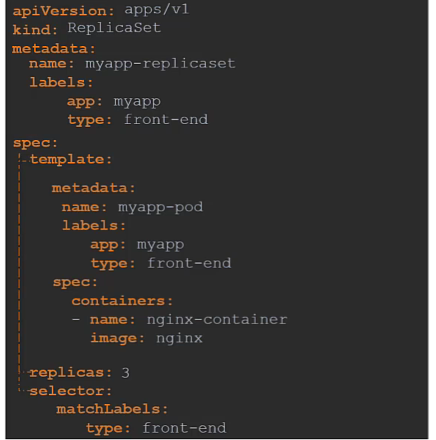
>간단히 말해, matchLabels는 리소스가 선택할 파드의 레이블을 지정하는 데 사용되며, 이를 통해 해당 리소스가 파드를 관리할 수 있다.
복제본의 수를 수정하는 명령어
1. kubectl replace -f replicaset-definition.yml (파일을 직접 수정)
2. kubectl scale --replicas=6 -f replicaset-definition.yml (복제본의 개수는 바뀌지만 실제 파일은 수정 안됌!!!)
3. kubectl scale --replicas=6 replicaset myapp-replicaset (type, name을 직접 입력)
13. deployments
디플로이먼트(Deployment)는 애플리케이션의 업데이트를 관리하고, 이를 통해 애플리케이션을 사용자들에게 제공하는 프로세스를 말합니다. 디플로이먼트는 소프트웨어의 새로운 버전을 안전하게 롤아웃하고, 필요한 경우 이전 버전으로 롤백하는 기능을 제공합니다.
그리고, 쿠버네티스(Kubernetes)에서 디플로이먼트(Deployment)는 레플리카셋(ReplicaSet)과 함께 작동하여 애플리케이션의 파드를 관리합니다.
14. services
쿠버네티스(Kubernetes)의 Services는 애플리케이션을 외부로 노출하고, 클러스터 내부에서 서로 통신할 수 있도록 도와주는 중요한 개념이다.
NodePort, ClusterIP, LoadBalancer 총 3가지 타입이 있다.
NodePort

>서비스가 노드의 포트로부터 pod까지 매핑해주는 역할이다.
노드포트는 30000 ~ 32767 사이에서 설정 가능하다.
selector 를 잘 활용해서 pod의 labels 를 매칭시켜주고 사용하면 된다.
Cluster IP
ClusterIP는 Kubernetes 클러스터 내부에서만 액세스 가능한 가상 IP 주소를 할당하여 서비스를 노출하는 방법이다.
LoadBalancer
LoadBalancer 서비스 유형은 클러스터 외부에서 액세스 가능한 외부 로드 밸런서를 생성하기 위한 방법이다.
다만 cluster IP와의 차이점은 로드 밸런서 타입의 서비스는 외부에서의 접근이 가능하고, 클러스터IP 타입의 서비스는 클러스터 내부에서의 접근만 가능하다.
15. name space
네임 스페이스는 작업공간을 뜻한다.
하나으 ㅣ클러스터에서 리소스를 분리시키는 역할을 해준다.
16. 명령형과 선언형
어떻게가 아니라 무엇을 해라 라고 명시하는것이 명령적 접근이다.
아래 예시를 보자.
선언적 명령 예시
kubectl run httpd --image=httpd:alpine --port=80 --expose선언적 명령은 명령어를 통해 직접 원하는 상태를 지정하는 방식이다.
즉, 운영자가 원하는 리소스 상태를 지정하고 Kubernetes가 해당 상태를 달성하도록 지시하는 방식이다.
이 명령은 다음과 같은 작업을 수행한다.
- kubectl run: 새로운 Pod을 생성하는 Kubernetes 명령입니다.
- httpd: Pod의 이름을 지정합니다.
- --image=httpd:alpine: 생성될 Pod에 사용될 이미지를 지정합니다. 여기서는 httpd:alpine 이미지를 사용합니다.
- --port=80: Pod 내부에서 노출할 포트를 지정합니다.
- --expose: 생성된 Pod에 대한 서비스를 자동으로 생성하도록 지정합니다.
즉, 이 명령은 "httpd"라는 이름의 Pod을 httpd:alpine 이미지를 사용하여 생성하고, Pod 내부에서 포트 80을 노출시키며, 이를 서비스로 노출시킨다.
명령적 명령 예시
명령적 명령은 직접 리소스의 상태를 변경하는 방식이 아니라, 원하는 상태를 지정하여 Kubernetes에게 달성하도록 요청하는 방식이다.
이를 위해 YAML 파일을 사용하여 리소스의 상태를 정의하고 kubectl apply 명령을 사용하여 해당 YAML 파일을 Kubernetes 클러스터에 적용한다.
예를 들어, 아래의 YAML 파일을 사용하여 Pod을 생성하는 경우를 생각해보자.
yaml
Copy code
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:latest
이 YAML 파일은 "nginx-pod"라는 이름의 Pod을 생성하며, 해당 Pod은 "nginx:latest" 이미지를 사용하는 컨테이너를 포함한다.
그런 다음 다음과 같이 명령을 실행하여 YAML 파일을 적용합니다.
kubectl apply -f nginx-pod.yaml
즉, 운영자가 직접 리소스의 상태를 변경하는 것이 아니라, 원하는 상태를 지정하고 Kubernetes에게 적용하도록 명령하는 것이다.
17. Kubectl Apply
내부적으로 apply 명령이 어떻게 동작할까?
apply는 로컬 구성 파일 뿐만 아니라 라이브 개체 정의를 고려하여 응용 구성도 고려한다.
즉, apply로 실행했을 때 pod 가 없으면 pod를 생성해준다.